Corpus Tutorial
By: Daniel A. Healy
This article will teach you how to use the BYU corpus system and how to run some basic searches on the corpora that are available there. If you do not know what corpora are, I invite you to visit the "Introduction to Corpora" page found in the Corpus section of our website.
Step 1: Entering the Corpus Website
Visit the BYU corpus website here, and you will be greeted with the following main page:
By: Daniel A. Healy
This article will teach you how to use the BYU corpus system and how to run some basic searches on the corpora that are available there. If you do not know what corpora are, I invite you to visit the "Introduction to Corpora" page found in the Corpus section of our website.
Step 1: Entering the Corpus Website
Visit the BYU corpus website here, and you will be greeted with the following main page:
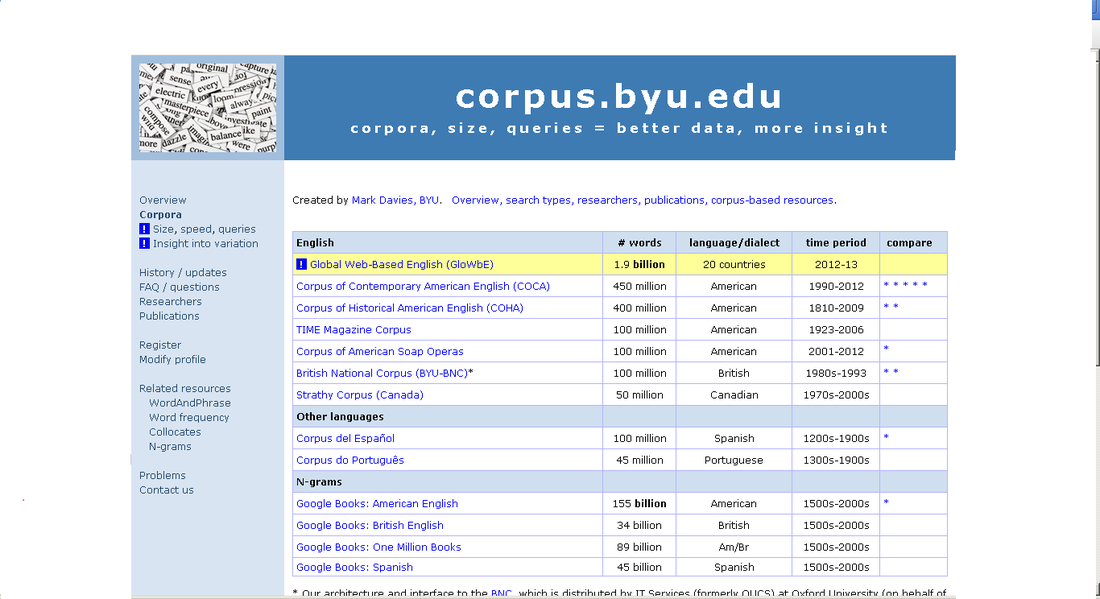
As you can see, there are many corpora available to choose from. The two I use the most frequently are the Corpus of Contemporary American English (COCA) and the Corpus of Historical American English(COHA). Some data about word count, languages used, and time period are also available. On the left hand side of the page you can register a free account. This is not required to use the corpus, but you will only be able to do a limited number of search queries without an account.
For this tutorial, I will be using COHA, but you can play around with any of the corpora on the website to see how they differ from each other.
Step 2: Entering the Corpus Page
Click the "Corpus of Historical American English(COHA)" link on the main page, then click the enter button on the COHA welcome page to enter the COHA search query system, which looks like this:
For this tutorial, I will be using COHA, but you can play around with any of the corpora on the website to see how they differ from each other.
Step 2: Entering the Corpus Page
Click the "Corpus of Historical American English(COHA)" link on the main page, then click the enter button on the COHA welcome page to enter the COHA search query system, which looks like this:

Step 3: Using the Corpus
We will not be examining every possible function of this system because I want to keep this tutorial concise, but when using corpora, there are 3 functions that are very important:
-Frequency Lists
-Collocation Searches
-Concordances
Frequency lists are just like what they sound: you enter a search term in the "Words" field, and it will return the frequency of that word, or the number of times that word appears in the corpus. Let's try searching for the word "frequency" in COHA:
We will not be examining every possible function of this system because I want to keep this tutorial concise, but when using corpora, there are 3 functions that are very important:
-Frequency Lists
-Collocation Searches
-Concordances
Frequency lists are just like what they sound: you enter a search term in the "Words" field, and it will return the frequency of that word, or the number of times that word appears in the corpus. Let's try searching for the word "frequency" in COHA:
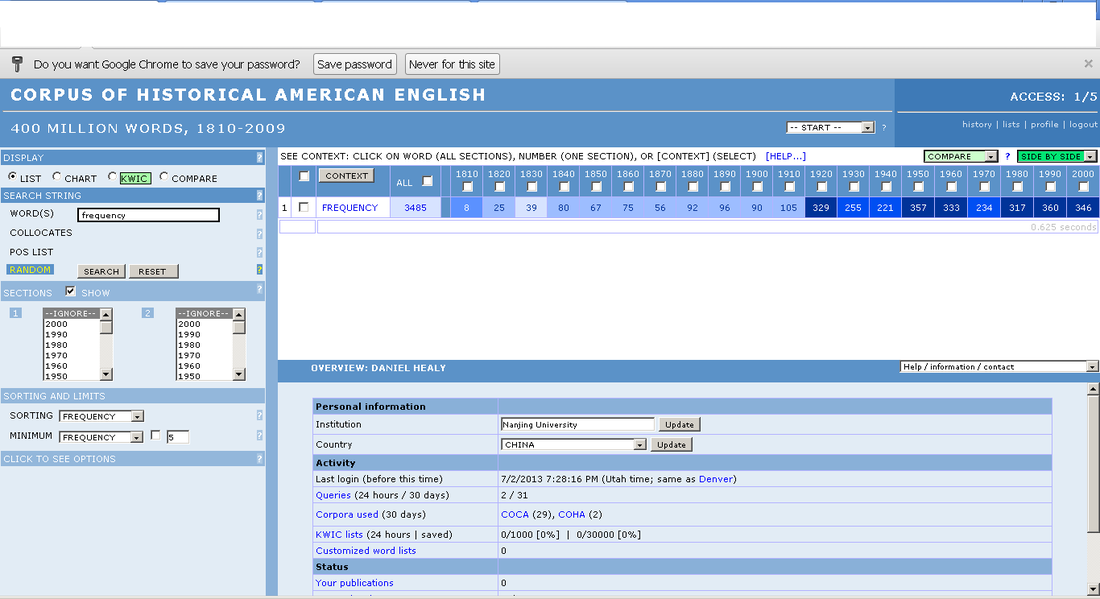
Here we can see that the word frequency occurs 3485 times in COHA. Because COHA is a historical corpus, this frequency list provides us with the distribution of the word frequency across different decades, with the 1950s having the highest frequency of 357 instances of the word. Frequency lists are useful because they can help show us whether a word is commonly used or not. The problem with frequency lists is that words have different meanings in different contexts, and a frequency list cannot tell us which sense of a word is more commonly used. This is where concordances come into play.
A concordance gives us the key word in context(KWIC) which allows us to make a judgment about which sense of the word is more commonly used. If we click the number "357" under the 1950s heading in our newly generated frequency list, we can see all 357 instances of the word "frequency" in the 1950s section of the corpus in context:
A concordance gives us the key word in context(KWIC) which allows us to make a judgment about which sense of the word is more commonly used. If we click the number "357" under the 1950s heading in our newly generated frequency list, we can see all 357 instances of the word "frequency" in the 1950s section of the corpus in context:

Here we can see each instance of the word "frequency" in the 1950s section of COHA. We also get data about the year the instance comes from, its text type, and even the publication name. We also see that our search term is bolded and underlined, and we get to see each term in context. This lets us get a better feel about how the words are used, rather than just how many times they are used.
Another function we need to know is collocation searches. A collocation is a group of words that are commonly found together. For example, if we want to know what word appears most frequently 1 word to the right of "frequency", we can do that search. To do it, click the word "COLLOCATES" at the left hand side near the words search field. After that, you will get 2 small drop down menus. One of these is the "Left collocate" drop down menu, the other is the "Right collocate" drop down menu. Here, you can have the engine search for collocations to the left and right of your main search term. For this example, I have selected "1" in the right drop down menu.
Another function we need to know is collocation searches. A collocation is a group of words that are commonly found together. For example, if we want to know what word appears most frequently 1 word to the right of "frequency", we can do that search. To do it, click the word "COLLOCATES" at the left hand side near the words search field. After that, you will get 2 small drop down menus. One of these is the "Left collocate" drop down menu, the other is the "Right collocate" drop down menu. Here, you can have the engine search for collocations to the left and right of your main search term. For this example, I have selected "1" in the right drop down menu.
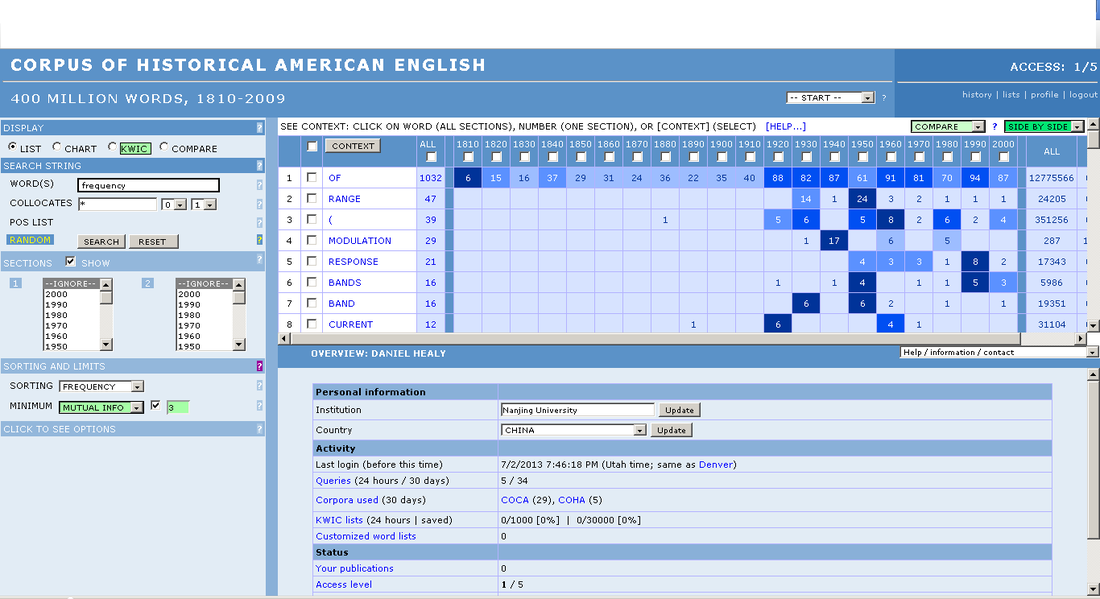
When I hit search, a frequency list appears for all the words that appear 1 word to the right of "frequency" in the corpus. We can see that "of" is the most common collocate for frequency, and before 1920, it more or less is the only one that occurs. After that time, we start to see words that appear to be scientific in nature, which seems to suggest that these instances of frequency refer to the scientific term, rather than the words common usage. In order to be sure, we would have to check the relevant concordance data, which we can do by clicking any of the numbers in the frequency list.
I hope this basic introduction to the functions of the BYU corpus system has given you enough information to start doing your own search queries. For more detailed information, check out the "External Resources" page for in-depth tutorials on corpus use and statistical methods for analyzing corpus data.
I hope this basic introduction to the functions of the BYU corpus system has given you enough information to start doing your own search queries. For more detailed information, check out the "External Resources" page for in-depth tutorials on corpus use and statistical methods for analyzing corpus data.
